如何改造智能助手实现 RAG
RAG 简介
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合检索和生成的技术,用于提升生成式 AI 模型(如 GPT 等)的能力和准确性。RAG 将外部知识检索与生成模型相结合,使模型能够基于实时或动态的数据生成更相关的答案。
RAG 的核心流程
检索阶段(Retrieval) :
- 从外部知识库(如文档数据库、向量数据库、搜索引擎)中检索与用户问题相关的上下文或信息。
- 检索到的内容可以是文本片段、表格数据等,通常通过语义搜索技术获取。
生成阶段(Generation) :
- 将检索到的上下文与用户问题结合,输入到生成式模型中。
- 模型利用这些上下文生成更准确、相关的回答。
RAG 的优势
- 实时性:通过外部知识检索,RAG 能够回答基于最新数据的问题,而不是依赖模型训练时的静态知识。
- 准确性:减少模型的“幻觉”问题(生成虚假或不相关内容),提高回答的相关性和可信度。
- 可控性:可以通过限制检索范围(如某一领域的知识库)来控制生成结果的质量和内容。
实现
文本向量化
RAG 是基于本地知识库的检索增强问答功能,首先第一步是需要对本地知识库的文档进行向量化存储,之后用于对问题的检索。
1. 嵌入模型
向量化存储需要用到向量数据库和嵌入模型。嵌入模型也就是 embedding model,可以将文档解析成一个多维向量,具体生成多少维的向量基于你选择的嵌入模型。
嵌入模型可以选在在线 API,很多模型厂商都提供嵌入模型的调用。我这里使用的是 Ollama 本地部署的嵌入模型,进入 Ollama 官网,搜索 embedding,我选择了第一个进行下载。
进入模型详情页,有介绍如何拉取模型,值得注意的是,一般嵌入式模型是不需要通过 ollama 运行的,只需要拉取就行了。 详情页有介绍:
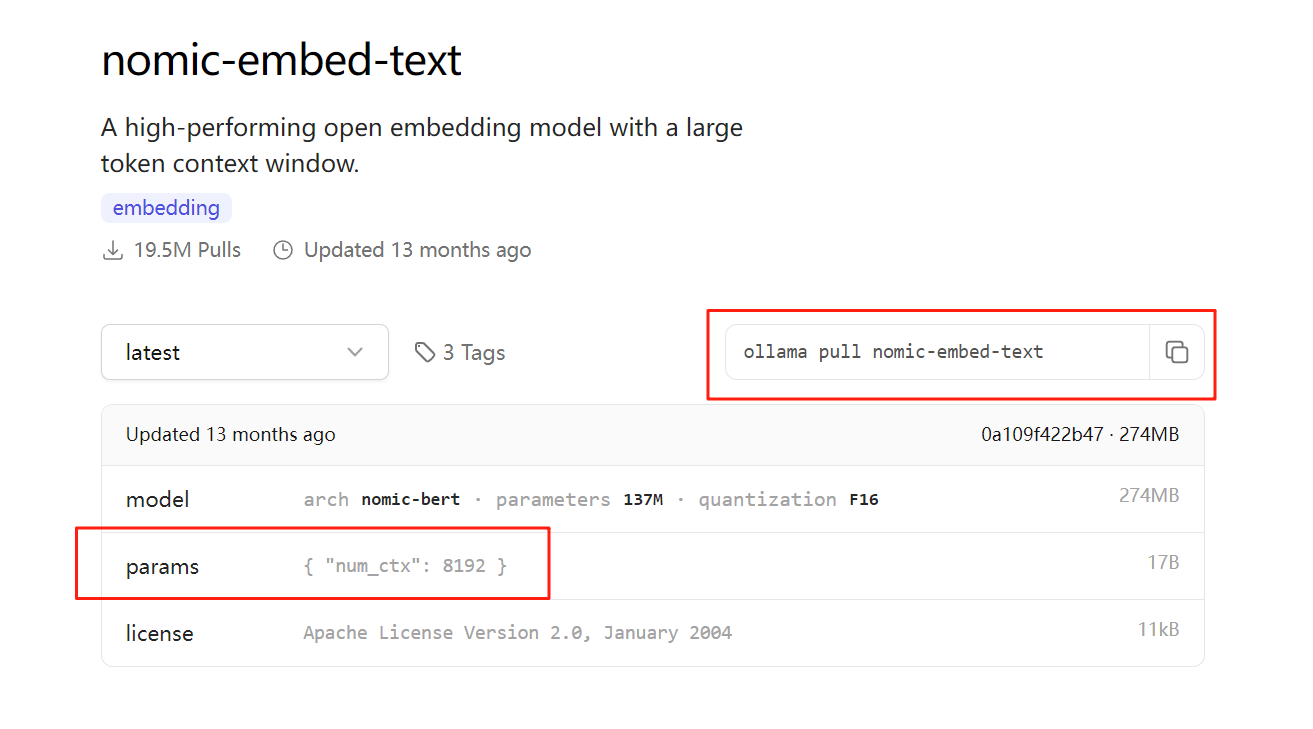
"num_ctx": 8192: 表示嵌入模型一次最多可以处理 8192 Tokens。这是模型的上下文窗口大小,用来限制输入文本的长度。
Spring AI 关于Ollama Embedding model中也有对这个参数的设置:
| Property | Description | Default |
|---|---|---|
| spring.ai.ollama.embedding.options.num-ctx | Sets the size of the context window used to generate the next token. | 2048 |
Spring AI 中设置的默认值是 2048,所以,如果通过 Spring AI 调用 Ollama Embedding model 会限制模型输入最多 2048 个 tokens。所以当输入的文本较长时,我们需要对文本进行分割处理。
当我们将嵌入模型拉取到我们本地安装的 Ollama 之后,我们就可以在 Spring AI 中集成文档向量化功能了。
2. Spring AI 集成 Ollama 嵌入模型
首先引入相关的依赖 pom.xml:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-elasticsearch-store-spring-boot-starter</artifactId>
</dependency>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-SNAPSHOT</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>这里把对话模型 openai 的依赖也一并引入了,值得注意的是,Spring AI 是支持 zhipu AI 大模型的,zhipu ai 模型支持 openapi 规范,所以我们可以使用 openai 的依赖来调用智普提供的 api。
通过配置 application.yml 就可以实现,代码如下:
ai:
openai:
api-key: ${ZHIPU_AI_API_KEY}
base-url: https://open.bigmodel.cn/api/paas/
chat:
api-key: ${ZHIPU_AI_API_KEY}
base-url: https://open.bigmodel.cn/api/paas/
completions-path: /v4/chat/completions
options:
model: GLM-4-flash
ollama:
base-url: http://localhost:11434
# ollama版本更新,spring ollama内置的api跟老版本ollama对应不上,导致报错:404。措施:升级ollama
embedding:
options:
num-batch: 512
model: nomic-embed-text相关的 API Key 可以去官网申请,我用的智普提供的免费模型 GLM-4-flash。
相关配置完成后,接着就开始实现文本嵌入功能,主要流程就是获取上传的文档内容,然后进行向量化,将向量化的数据保存到向量数据库,同时保存一些元数据信息,用于检索时使用。
主要代码如下:
@Component
@Slf4j
public class Embedding {
private final ElasticsearchVectorStore vectorStore;
public Embedding(ElasticsearchVectorStore vectorStore) {
this.vectorStore = vectorStore;
}
public void save(String content, Map<String, Object> meta) {
Document document = new Document(content, meta);
vectorStore.doAdd(List.of(document));
}
}TIP
文档参数 meta,顾名思义就是元数据的意思,在保存文档时,可以添加一些元数据信息,比如文档的标签、标题、时间、作者等等...
TIP
如果文档过长,向量化之前需要先对文档进行分割处理。 Spring AI 提供了默认的分割方式,这种分割方式不够智能,会将文档语义切分,而且在保存时随机生成每个子文档的 ID,如果要删除嵌入文档,会比较麻烦。
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> splitDocs = splitter.split(doc);
vectorStore.doAdd(splitDocs);这里的 vectorStore 就是我们引入的 ES 向量数据库,使用 add 命令就同步完成了文档向量化操作和文档的保存。
我们也可以对 vectorStore 做一下自定义配置:
@Bean
public ElasticsearchVectorStore vectorStore(OllamaEmbeddingModel embeddingModel,
RestClient restClient) {
ElasticsearchVectorStoreOptions options = new ElasticsearchVectorStoreOptions();
options.setIndexName("ai-knowledge"); // 设置es索引名称
options.setDimensions(768); // 设置向量化的维度大小
return new ElasticsearchVectorStore(options, restClient, embeddingModel, true);
}3. 检索问答
当然在我们进行检索问答前,你自己需要实现文档上传功能,上传功能中调用文档向量化组件用来将文档保存到向量数据库中。
当用户提问时,问题需要先向量化处理后去向量数据库中检索相似度最高的几段文本返回,这几段文本作为问题的上下文结合问题一起发送给大模型,大模型就基于这个上下文进行回答。这就是 RAG 的主要思想。非常简单,就是提供更加丰富的信息给大模型,让它回答的更准确。
下面是流式回答的实现代码:
@Configuration
public class ChatClientConfig {
private final OpenAiChatModel openAiChatModel;
private final ElasticsearchVectorStore vectorStore;
public ChatClientConfig(ElasticsearchVectorStore vectorStore, OpenAiChatModel openAiChatModel) {
this.openAiChatModel = openAiChatModel;
this.vectorStore = vectorStore;
}
@Bean
public ChatClient ragChatClient() {
return hatClient.builder(openAiChatModel)
.defaultAdvisors(
new MessageChatMemoryAdvisor(new InMemoryChatMemory()),
new QuestionAnswerAdvisor(vectorStore)
)
.build();
}
}
@RestController
@RequestMapping("/api/v1/rag")
@Slf4j
public class RagChatController {
private final ChatClient ragChatClient;
public RagChatController(ChatClient ragChatClient) {
this.ragChatClient = ragChatClient;
}
@GetMapping("/chat")
public Map<String, String> generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
String response = this.ragChatClient.prompt()
.advisors(advisor -> advisor.param("chat_memory_conversation_id", "678")
.param("chat_memory_response_size", 100))
.user(message)
.call()
.content();
return Map.of("generation", response);
}
}- MessageChatMemoryAdvisor 是用于实现对话记忆。对话 id:678 一般前端随机生成,用于管理对话历史。
- QuestionAnswerAdvisor 是用于实现 RAG 的。